●AIの精度は入力データによって決まる
ひとつめは「Garbage In, Gargage Out: How Purportedly Great Machine Learning Models can be Screwed Up by Bad Data」という講演。発表者はソフォスのデータサイエンティスト Hillary Sanders氏。
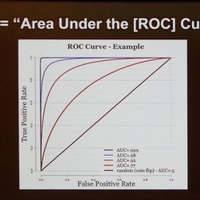
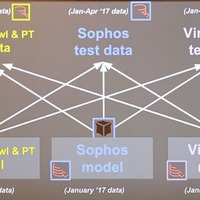
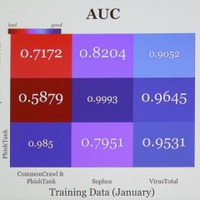
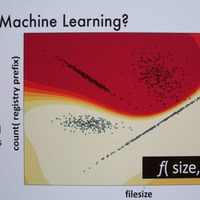
内容はAI(機械学習:ML)モデルの学習データ、テストデータによる判定精度の評価について。それをどのように実運用への精度につなげるかを分析したものだ。分析方法は、3つのマルウェア判定MLモデルに、お互いのテストデータを評価させる。判定精度のばらつきを調べることで、学習データやテストデータと実運用下でのリアルデータとの違いを示し、より精度の高いAIモデルを作るヒントをさぐるという。
この調査でSanders氏が主張するのは「セキュリティ系のML研究者が示すAIモデルの精度はあてにならない。なぜなら楽観的な予測に引きずられているからだ。重要なのは、そのバイアスを認識し、厳密な予想で評価すること。そうすれば、ゴミを吐くMLモデルにしないで済む」ということだ。
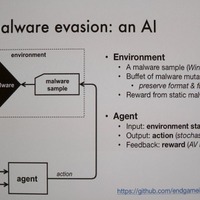
MLモデルの作り方をきわめて簡単に説明すると、特定の評価関数に大量の学習データを与えながら、結果に応じて関数の評価式、パラメータを調整していくことで、判定精度を上げていく(学習)。その後、学習データとは別のテストデータ(一般的には特定期間に採集した生データ)を評価させて(テスト)最終的な確認を行いモデルを完成させる。完成したモデルはスタティックなもので入力に対して評価結果を出力するだけで、じつは内部的にはインテリジェントな処理を行っていない。
しかし、学習データはMLの開発者、エンジニアが用意しパラメータ等の調整もエンジニア、つまり人間が行う。そのため、ラボ内での学習とテストでは良好な成績だったとしても実際のデータを処理させたときに精度がでないことがある。
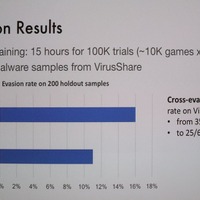
そこでSandars氏は、「異なる学習データとテストデータを用いることで、より精度を高める学習データセットの作り方、テストデータによるモデル精度の変化をどうとらえるかを分析することにした」という。
ひとつめは「Garbage In, Gargage Out: How Purportedly Great Machine Learning Models can be Screwed Up by Bad Data」という講演。発表者はソフォスのデータサイエンティスト Hillary Sanders氏。
内容はAI(機械学習:ML)モデルの学習データ、テストデータによる判定精度の評価について。それをどのように実運用への精度につなげるかを分析したものだ。分析方法は、3つのマルウェア判定MLモデルに、お互いのテストデータを評価させる。判定精度のばらつきを調べることで、学習データやテストデータと実運用下でのリアルデータとの違いを示し、より精度の高いAIモデルを作るヒントをさぐるという。
この調査でSanders氏が主張するのは「セキュリティ系のML研究者が示すAIモデルの精度はあてにならない。なぜなら楽観的な予測に引きずられているからだ。重要なのは、そのバイアスを認識し、厳密な予想で評価すること。そうすれば、ゴミを吐くMLモデルにしないで済む」ということだ。
MLモデルの作り方をきわめて簡単に説明すると、特定の評価関数に大量の学習データを与えながら、結果に応じて関数の評価式、パラメータを調整していくことで、判定精度を上げていく(学習)。その後、学習データとは別のテストデータ(一般的には特定期間に採集した生データ)を評価させて(テスト)最終的な確認を行いモデルを完成させる。完成したモデルはスタティックなもので入力に対して評価結果を出力するだけで、じつは内部的にはインテリジェントな処理を行っていない。
しかし、学習データはMLの開発者、エンジニアが用意しパラメータ等の調整もエンジニア、つまり人間が行う。そのため、ラボ内での学習とテストでは良好な成績だったとしても実際のデータを処理させたときに精度がでないことがある。
そこでSandars氏は、「異なる学習データとテストデータを用いることで、より精度を高める学習データセットの作り方、テストデータによるモデル精度の変化をどうとらえるかを分析することにした」という。