AI のプロンプトに工夫をこらして秘密情報を答えさせるなど、一般に「攻撃側による AI 利用」といえば、こうした「プロンプトエンジニアリング」がまず思い浮かぶ。
だが、そんな AI のガードレールをそろりそろりと迂回するような遠回りをしなくてもたとえば「親父、マルウェア大盛り一丁!」「喜んで!」そんな風に直球ストレートで AI にマルウェアを作らせる方法はないか。そう考えるエンジニアがいても不思議はない。
2025年の Black Hat USA で発表された「Training Specialist Models : Automating Malware Development」は、そんな発想から生まれた研究だ。
発表者はカイル・アベリー氏(写真)。オランダに拠点を置くレッドチーム専門企業 Outflank での研究開発( R&D )エンジニアだ。Outflank はレッドチーム向けの商用攻撃シミュレーションツール「Outflank Security Tooling」で知られ、2023 年にサイバーセキュリティ大手の Fortra(旧 HelpSystems )に買収されている。カイル自身はレッドチームのバックグラウンドを持ち、自称「 AI 愛好家」だという。一体どんな風に AI を「愛好」しているのか。本稿で迫ってみる。
彼の発表は「いかに AI にマルウェアを書かせるか」それも「なるべく安く簡単に」という点にフォーカスした開発手法を提案するものだった。「なるべく安く簡単に」というのはもちろん法人の予算規模であるはずはなく、あくまで個人のポケットマネーでホストできる規模の AI リソースで、いかにマルウェアコーディングを自動化するかにある。
●高度な AI は高い・安い AI は使えない
カイルは、レッドチームのバックグラウンドを持ち、攻撃的セキュリティ研究の専門家だ。AI に関して、機械学習他の正式な教育を受けたわけではない。趣味的に AI、とくに大規模言語モデル(LLM)を使って回避型のシェルコードローダーを開発する手法を考えていたという。
AI にマルウェアを開発させようとしてもうまくいかない。カイルのスタートラインはまずこれを克服することだ。一般的な AI モデルはマルウェアを生成しないようにチューンされている。そのためプロンプトエンジニアリングなどを駆使する必要がある。これを回避するため、自前のモデルをローカルで動かせば、マルウェアを喜んで生成してくれる AI をトレーニングすることができる。だが、彼は AI 愛好家であって研究者ではない。独自のモデルを開発することはできない。商用 LLM やオープンソースを利用することになる。しかし、ここでも壁にぶつかる。
「 LLM でマルウェア開発を自動化するというチャレンジを考えたとき、現在の LLM があまりうまく機能しない問題に直面しました。現在の LLM は大きく 2 つのタイプに分けられます。ひとつは、OpenAI、Google、Anthropic など企業にとっては有用でとても高性能なモデル。これは、サイズやコストの面で自分でホストすることができない。オープンソースなら小規模なモデルが存在するが、ローカルでホストするのに問題はないが、いかんせんちゃんとしたコードを吐いてくれません」
●札束で殴れないときは、機能特化型で
大規模モデルが賢いのは、事実ベースのデータに基づく知識の量、そして推論能力を格納するパラメータの数が多いからだ。カイルの整理によれば、モデルの品質は「スキルの数」と「スキルあたりの品質」の掛け合わせで決まる。大規模モデルはスキルの数で圧倒するが、小規模モデルでもスキルを絞り込めば、スキルあたりの品質では大規模モデルに匹敵しうる。

ローカルでホストする場合、プロセッサ、GPU 資源などが限られるのでモデルは小さくせざるを得ない。小規模なオープンソースモデルの精度が低いのはこのためだ(実際、LLM の先端技術や商用モデルの世界では、GPU、電力、そしてトレーニングデータといった「物量=札束で殴る」が正義になっている)。
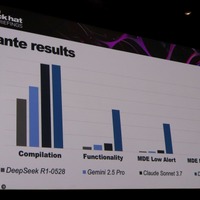
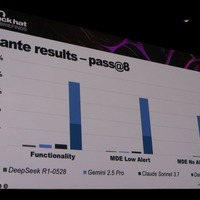
しかし、彼が求めているのはセキュリティシステム(例えば Microsoft Defender for Endpoint)を回避できるシェルコードローダーだ。
「汎用的な AI よりも、マルウェア作成という特殊なスキルに特化した AI モデルがあれば十分でした。スキルを限定してトレーニングを重ねれば、モデルサイズが小さく(= ローカルホストが可能)ても、マルウェア生成に特化した AI ができるのではないか。スキルを限定すれば、同じモデルサイズでも、スキルあたりの性能は大規模なモデルに負けないものができる、というのが僕の仮説でした」
専門の AI 研究者にとっては、この考え方に異論や突っ込みどころはあるのかもしれない。しかし、AI の専門家ではないカイルは、そんなことは気にせず実装してみることにした。
●思考の連鎖から推論モデルへ、そして RLVR へ
カイルの手法を理解するために、まず LLM の進化の流れを整理しておきたい。
LLM のトレーニングは大きく 2 段階に分かれる。膨大なインターネットデータから次のトークン(単語)を予測して学習する事前トレーニングと、チャットボットとして指示に従い回答できるよう調整する事後トレーニングだ。事後トレーニングには、教師あり微調整( SFT:Supervised Fine-Tuning )で指示応答のフォーマットを学ばせた後、人間からのフィードバックによる強化学習( RLHF : Reinforcement Learning from Human Feedback )で出力品質を高める手法が広く使われてきた。

ここでひとつ重要な発見があった。Google の研究で、LLM に「考える過程」を明示的に出力させる、いわゆる連鎖的思考( Chain-of-Thought )プロンプティングを行うと、数学問題の正答率が劇的に向上することが示されたのだ。たとえば PaLM 540B モデルでは、数学の文章題( GSM8K )の正答率が標準的なプロンプトでは低かったものが、Chain-of-Thought を使うと大幅に改善した。
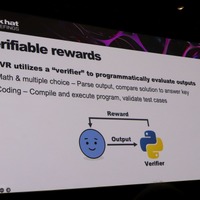
OpenAI はこの知見をさらに進め、モデルが常に Chain-of-Thought を使って推論するようトレーニングした「推論モデル」(o1 シリーズ)を開発した。その事後トレーニングには、人間のフィードバックではなく検証可能な報酬を伴う強化学習( RLVR : Reinforcement Learning with Verifiable Rewards )が使われた。数学の国際コンテスト問題( AIME )で、従来の GPT-4o の正答率 9 %に対し、o1 は 74 %を達成している。
続いて DeepSeek がオープンソースの推論モデル R1 を公開し、そのトレーニング手法を詳細に公開した。RLVR のアルゴリズムとして採用されたのが GRPO( Group Relative Policy Optimization )だ。
RLVR の仕組みを直感的に理解するには、従来の RLHF との違いを押さえるとわかりやすい。
RLHF では、AI の出力を人間が「 A と B どちらの回答が良いか」と評価し、その好みのデータで「報酬モデル」と呼ばれる別の AI を訓練する。AI はこの報酬モデルから高いスコアをもらえるように学習する。いわば人間の「目利き」を模倣した AI 審査員を介して学ぶ仕組みだ。高品質な結果を得られる反面、大量の人手による評価が必要でコストがかかる。