本稿は自動脆弱性診断ツール「AeyeScan」を開発する株式会社エーアイセキュリティラボが、セキュリティテストの自動化、脆弱性診断の内製化、AI/機械学習などの技術情報の共有を目的とした記事です。
今回は、深層学習で CAPTCHA を突破してみたいと思います。
1.問題設定
弊社では自動巡回型の Webアプリケーション脆弱性診断サービスを提供しております。
また、認証機能に関連する以下のような機能を提供しております。
1) 簡単なパスワードを使用できないか調べる検査を追加
2) 高頻度でログインを試行できないか調べる検査を追加
3) CAPTCHA を簡単に突破できないか調べる検査を追加
今回は (3) に関連して、有名な CAPTCHA を突破できないか実験してみたいと思います。
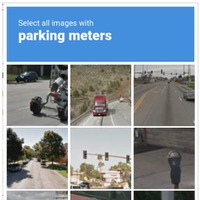
CAPTCHA とは、画像や音声等の読み取りを利用者に行わせることで、ボットなどの自動化されたプログラムのアクセスを防ぐ仕組みです。有名なものでは、Google社の提供する「reCAPTCHA v2」があります。これは、提示されたテーマに合致する画像を選択することで、人間によるアクセスであることを示す仕組みです。
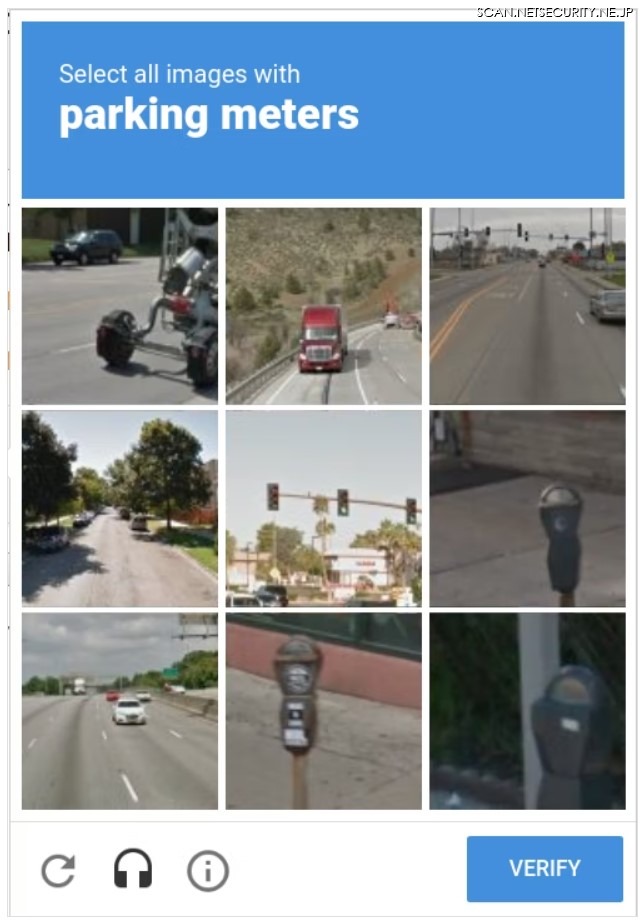
この他にも、画像に書かれた文字を読み取る方式もよく見かけます。

今回は、CAPTCHA の中でも比較的シンプルで解きやすそうに見える、「securimage」(https://www.phpcaptcha.org/ )という CAPTCHA を突破の対象にします。securimage は PHP で書かれたオープンソースの CAPTCHA であり、”PHP CAPTCHA”で検索すると上位に表示される有名な CAPTCHA です。
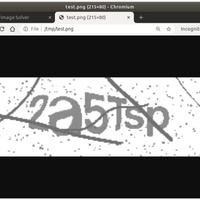
securimage という名前は聞いたことがないという方も、以下のような画像は見たことがあるかもしれません。散らばった黒い点と不規則に入る線、歪んだ文字が特徴的です。

securimage は文字の表示される場所や大きさ、形が画像毎に異なります。そのため、プログラマが CAPTCHA の特徴をもとに文字識別のルールを考え、それをプログラムに書き起こすというアプローチでは突破がやや難しそうです。
深層学習は、画像を与えて文字の特徴そのものを学習させることができるため、文字の場所や大きさ、形が変わる場合にも対応できそうです。デメリットとして、学習データを用意する必要がありますが、securimage はオープンソースであり、手元で自由に画像データを作成することができるため、今回は問題にはなりません。そのため、今回は深層学習のアプローチで突破を行います。
なお、今回は 2013 年リリースの古いバージョンである securimage ver.3.5 をデフォルト設定で利用するケースを対象とします。
2.サンプルデータ作成
まずサンプルデータを集めます。これは CAPTCHA の画像とその答えのペアを集めるということです。
サンプルデータを集めるためには、securimage を少し修正する必要があります。なぜなら securimage は、HTTPサーバに設置する想定で作られており、リクエストを受け取ると画像データのレスポンスを返すように作られているためです。そのままではレスポンスヘッダ等の不要なデータも含めてを返してしまいます。また、答えの情報も PHP のセッションに保存されるのみで外部には出力されません。そのため、今回は、答えを名前に持つ pngファイルを出力するコマンドライン用のスクリプト(https://github.com/AsaiKen/securimage_solver_for_blog/blob/master/securimage/securimage_save.php )を作成します。
ファイルを出力させる方法は、
(https://github.com/dapphp/securimage/blob/3.5/securimage.php#L1389 )の
imagepng($this->im);
を
imagepng($this->im, "{$this->output_dir}/{$this->code_display}.png");
に変えて、ファイル出力するようにしています。
このスクリプトを利用して、訓練用 500000 枚、訓練中の評価用に 10000 枚、テスト用に 10000 枚を用意しました。
3.モデルの選択
続いて、深層学習のモデルを選びます。自分で試行錯誤して作るのも面白いとは思いますが、今回は時短のために、今回の問題と似た問題を高い精度で解いている既存モデルを利用します。
「text recognition deep learning」などで検索して良さそうなモデルを探します。有り難いことに、モデルを一覧表で比較しているページがありました。
https://github.com/hwalsuklee/awesome-deep-text-detection-recognition
今回は、このリストの中で
https://github.com/clovaai/deep-text-recognition-benchmark
を使うことにしました。理由は、比較的新しいモデルである、スコアが高い、pytorch利用なので個人的に扱いやすい、そして使い方が詳細に記載されているためです。
さて、この「deep-text-recognition-benchmark」のソースを見てみると、縦横が 32x100 の画像を入力するモデルであること、gt.txt というサンプルデータを一覧化したファイルを用意する必要があることがわかります。そこで以下のスクリプトを追加し、画像サイズの変換、gt.txt の作成を行いました。
https://github.com/AsaiKen/securimage_solver_for_blog/blob/master/deep-text-recognition-benchmark/securimage/resize.py
https://github.com/AsaiKen/securimage_solver_for_blog/blob/master/deep-text-recognition-benchmark/securimage/create_gt_file.py
4.訓練と評価
サンプルデータとモデルの用意ができたので、モデルを訓練します。ここは、https://github.com/clovaai/deep-text-recognition-benchmark
に使い方が詳細に書いてあるため、その通りに実行するだけです。なお、ここでも「deep-text-recognition-benchmark」のソースを一部修正する必要がありましたが、些細な修正なので割愛します。
$ CUDA_VISIBLE_DEVICES=0 python3 train.py \
--train_data ../../data/resize/train --valid_data ../data/resize/validate \
--select_data / --batch_ratio 1 \
--Transformation None --FeatureExtraction VGG --SequenceModeling BiLSTM --Prediction CTC \
--sensitive
続いてテストです。
$ CUDA_VISIBLE_DEVICES=0 python3 test.py \
> --eval_data ../data/resize/test \
> --Transformation None --FeatureExtraction VGG --SequenceModeling BiLSTM --Prediction CTC \
> --sensitive \
> --saved_model saved_models/None-VGG-BiLSTM-CTC-Seed1111/best_accuracy.pth
No Transformation module specified
model input parameters 32 100 20 1 512 256 63 25 None VGG BiLSTM CTC
loading pretrained model from saved_models/None-VGG-BiLSTM-CTC-Seed1111/best_accuracy.pth
dataset_root: ../data/resize/test dataset: /
sub-directory: /. num samples: 10000
97.45
サンプルデータを用意して手順通りに学習するだけで、正解率 97.45 % になりました。この正解率は、もしかすると人間の私より高いかもしれません。ハイパーパラメータをチューニングすればもう少し上がるかもしれませんが、十分な性能ですので、今回はここでやめておきます。
5.サービス化
せっかくなので Webサービスにして、外部から CAPTCHAソルバとして利用できるようにしてみます。python であれば flaskライブラリを使うことで簡単にこれを実現できます。
securimage_solver_for_blog/app.py at master AsaiKen/securimage_solver_for_blog GitHub
https://github.com/AsaiKen/securimage_solver_for_blog/blob/master/deep-text-recognition-benchmark/web/app.py
さっそく起動して試してみましょう。以下のコマンドで起動します。
$ python3 web/app.py
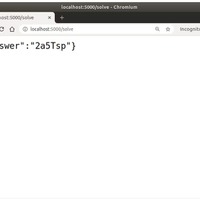
http://localhost:5000/ にアクセスします。
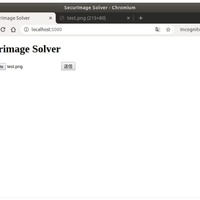
以下のファイルをアップロードしてみます。

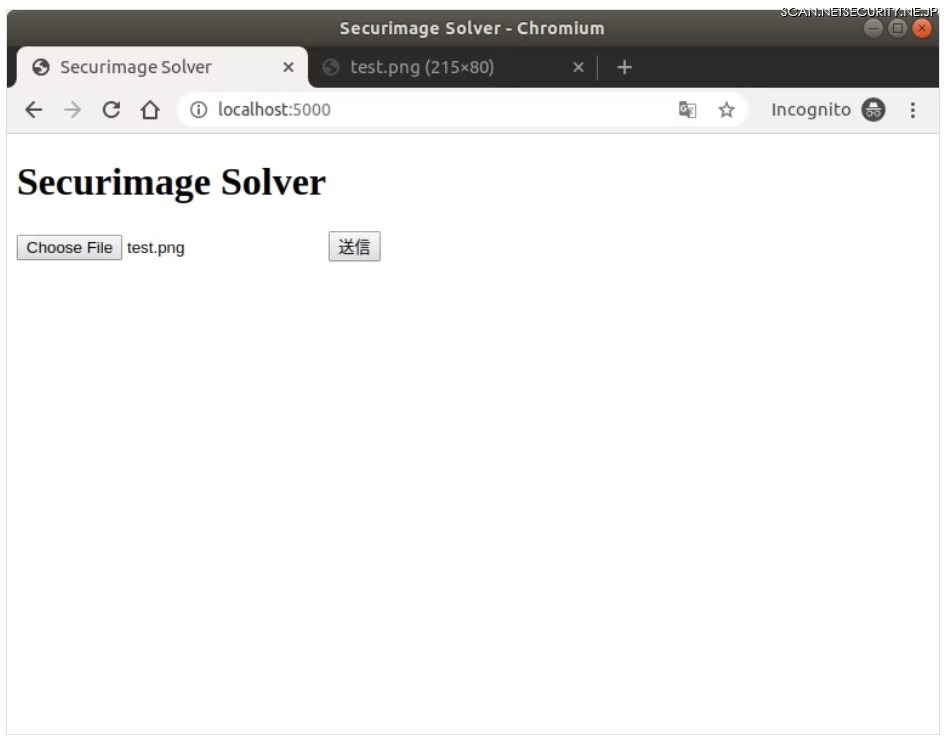
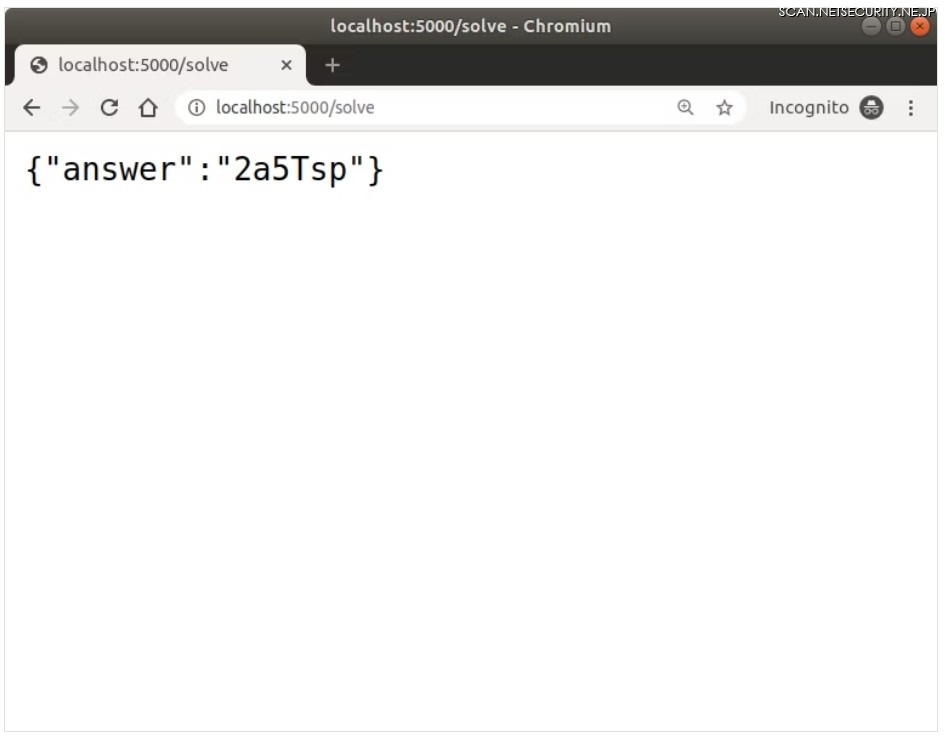
正解です。最後の p を R と間違えてしまうのではないかと思いましたが、ちゃんと p と認識できています。凄い。
6.最後に
いかがでしたでしょうか。今回は securimage を深層学習で突破できないか試してみました。その結果、性能の良い既存モデルを利用することで、特に工夫をしない状態でも 97 % の正解率で突破できることがわかりました。
ただし、今回の実験では、securimage をデフォルト設定で利用しています。securimage は設定でノイズの度合いや文字の種類を変更できるため、今回のモデルでは別設定の securimage を突破できないかもしれません。汎用的な securimage のソルバを作る場合は、ランダムに設定を変えてサンプルデータを集めるなどの工夫が必要となると思います。
ソースコード一式は以下の URL に置いておきます。
https://github.com/AsaiKen/securimage_solver_for_blog/tree/master/deep-text-recognition-benchmark