本稿は SaaS型Webアプリ診断ツール「AeyeScan」を運営している株式会社エーアイセキュリティラボが、セキュリティテストの自動化、脆弱性診断の内製化、AI/機械学習などの技術情報の共有を目的とした記事です。
今回は、実際に問題解決に機械学習を使ってみたいと思います。
1.問題設定
弊社では自動巡回型の Webアプリケーション脆弱性診断サービスを提供しております。
自動巡回では、ある URL にアクセスし、そのページにあるリンクやフォームを静的に解析したり、リクエストが発生する操作を動的に探して実行するなどして、次にアクセスするべき URL を探します。そして、これを繰り返し行い、Webアプリケーション全体をできる限り広く、そして速くアクセスすることを目指します。
こうした自動巡回を実装する際には、様々な問題に直面します。例えば、
・フォーム要素に正しい値を入力できず、投稿完了まで進むことができない
・フォーム入力エラーに気づかず、投稿に成功しているつもりで巡回してしまう
・CAPTCHA を突破できず、次の画面に進むことができない
・2要素認証があるためメールや携帯電話を経由しないとログインできない
・ログアウトやセッションエラーが発生していることに気づかず、ログインしているつもりで巡回を進めてしまう
・パスワードを変更してしまい、ログインができなくなる
・URL は異なるが同じレイアウトであるページ(ブログの記事など)が大量にある場合に、それらに 1 つずつアクセスしてしまい、巡回に時間がかかり過ぎてしまう
などがあります。
今回はこうした問題の内、フォーム要素に正しい値を入力できない問題を機械学習で解決できないか試してみたいと思います。
まずは機械学習モデルの入力情報を何にするかを考えます。
人間はフォームを見てフォーム要素に何を入力するか決めているので、フォームの画像を入力情報にできるのが理想です。しかし、これを実現するためには、フォーム画像と正しい入力値のペアを大量に用意してモデルに学習させるか、同様の課題を解決している既存モデルを再利用する(これは転移学習と呼ばれます)必要がありそうです。今回はどちらも難しそうなので、人間が経験則に基づいて特徴量設計を行い、少ないサンプルデータでも学習できるようにしたいと思います。
人間がフォームを見て、そこに何を入力するかを考える際には、フォームのレイアウト(入力欄の左側にラベルがあるタイプ、上側にラベルがあるタイプなど)やフォーム要素の付近にある文字列などを見るかと思います。今回は付近にある文字列に着目して、フォーム要素の近くにある文字列を抽出して、それをモデルの入力情報としたいと思います。
次に機械学習モデルの出力情報を何にするかを考えます。これはフォーム要素に入力する文字列です。ただ、任意の文字列を出力するとなると、使えるモデルが限定されてしまい、モデルの比較がしにくいことと、フォーム要素に入力する値はせいぜい数十種類程度であることを考慮して、任意の文字列ではなく、使用頻度が高い文字列のみを対象にすることにしました。これらの文字列をカテゴリとみなして、モデルの出力情報に利用します。
対象とするカテゴリは以下の 26 種類です。
メールアドレス
姓名
姓名(カタカナ)
姓
名
姓(カタカナ)
名(カタカナ)
電話番号(全桁)
電話番号(ハイフンあり、全桁)
電話番号(上2,3桁)
電話番号(中4桁)
電話番号(下4桁)
郵便番号(全桁)
郵便番号(上3桁)
郵便番号(下4桁)
都道府県 区市町村 番地
区市町村 番地
区市町村
番地
建物名
会社名
部署名
年
月
番号
任意
見てみるとわかりますが、同一の項目でもカタカナを入力するものや、分割して入力するものがあり、簡単な問題ではなさそうです。
2.サンプルデータ作成
ではまずサンプルデータを集めたいと思います。これはフォーム要素の近くにある文字列と正しいカテゴリのペアを集めるということです。
まずはフォーム内にあるすべての文字列を集めます。方法としては、以下の 2 つが思い浮かびました。
・ヘッドレスブラウザでページをレンダリングし、ブラウザ内で JavaScript を実行して、フォーム内のテキストを座標情報とともに抽出する
・ヘッドレスブラウザでページをレンダリングし、フォームを含むページのスクリーンショットを取得する。そしてスクリーンショットを OCR してテキストを座標情報とともに抽出する
ところで、サンプルデータを作る際は人間が目で見て、正しいカテゴリを付ける必要があります。そして、このプロセスを行うためにスクリーンショットを取得する必要がありそうです。これを考慮して、今回は後者のスクリーンショットから抽出する方式を採用しました。
ではまずフォームが存在するスクリーンショットを集めます。
最初に「お問い合わせフォーム」「ユーザー登録」「会員登録」「登録フォーム」などのキーワードで Google検索してフォームがありそうな URL を集めます。筆者は手動でブラウザで検索して、開発者ツールのコンソールからJavaScript で URL を抽出しました。そして、Puppeteer を利用した以下のようなスクリプトで URL からフォーム情報を集めます。
https://github.com/AsaiKen/form_inputter_for_blog/blob/master/js/crawler.js
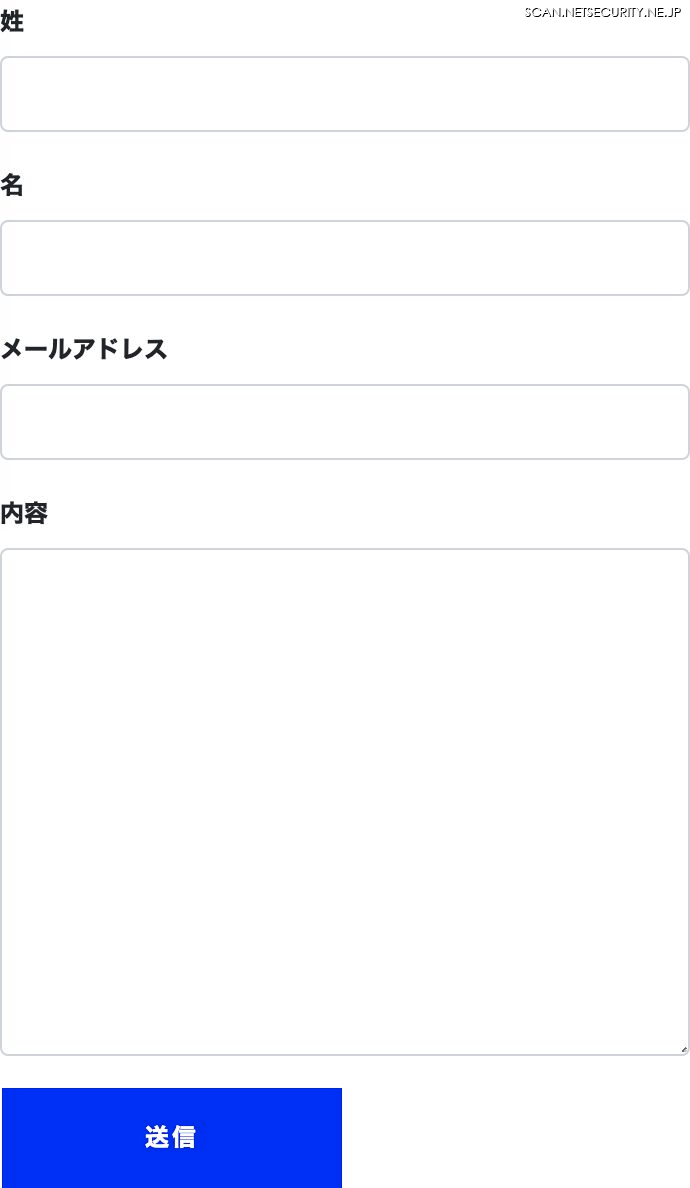
これによりフォームのスクリーンショット、そして以下のようなフォーム要素の位置情報を集めました。
スクリーンショット
フォーム要素の位置情報
https://gist.github.com/AsaiKen/97c36796663e1b781e497cb51d0ca61f
さて続いて、フォームのスクリーンショットから OCR でテキストと位置を抽出します。これには OpenCV と tesseract を利用しました。詳しくは以下のソースを見てもらうとして、簡単に説明すると、OpenCV で OCR しやすいように画像を加工し、tesseract で OCR しています。
ソースコード
https://github.com/AsaiKen/form_inputter_for_blog/blob/master/image_to_labels.py
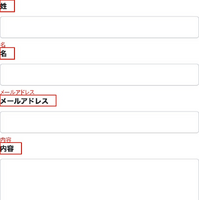
わかりにくいのでデバッグ用の画像も用意しました。以下のように、画像からテキストを抽出できていることがわかります。
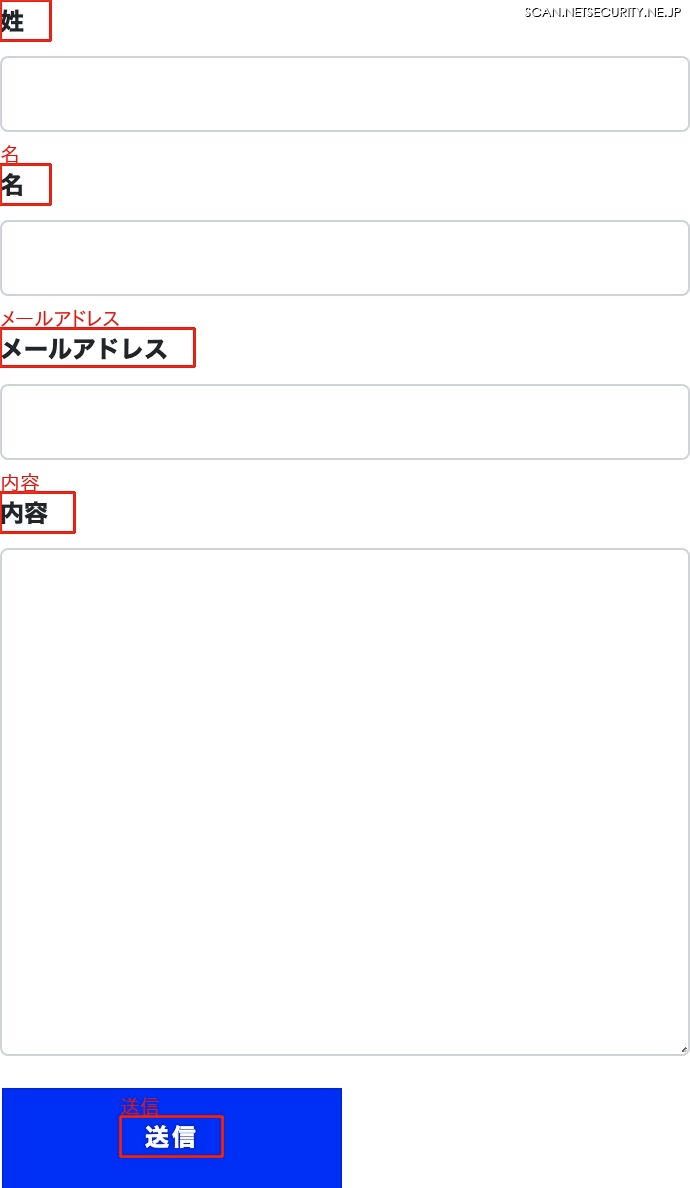
さて、フォーム内のテキストを集めましたが、ここからフォーム要素の近くにあるテキストだけを抽出します。今回は経験則に基づいて、フォーム要素と重なる位置、左側、直下、上側、下側の優先順位でテキストを探すようにしました。また、テキストのままでは定量的な値ではないため、テキストを形態素解析で単語に分割し、さらに Bag-of-Words と呼ばれる、単語の並びを単語の使用回数に変換するアルゴリズムで定量化しました。
ソースコード
https://github.com/AsaiKen/form_inputter_for_blog/blob/master/label_to_vector.py
これによりフォーム要素の近くにある単語は以下のようなベクトルに変換されます。これを入力値として利用します。
単語
['メールアドレス', '必須', '確認']
ベクトル
[0.021845164673652898, -0.1370634965993013, 0.02090792122768325, 0.05907568343663375, -0.00040289410537236274,
-0.06704381291305278, -0.0829317999508743, -0.10872835004423063, 0.3730504611445818, -0.4246466438140218,
0.04802730257114213, -0.03818767369999278, -0.005551020410021278, 0.7772829830549164, -0.0748911375106632,
0.26122716537928736, -0.02624689892263843, 0.02702105314136291, -0.10996364861363872, 0.11928573440614244,
-0.1772051704267784, 0.021298528308290238, 0.0003896265441465825, -0.41791384624712263, -0.09545624845487635,
0.8989255840525021, 0.3329174008555454, 0.19488423074814692, 0.16799672110906763, 0.2521528720694286]
次は各フォーム要素に対する正しいカテゴリを作成します。この作業は、スクリーンショット内にあるフォーム要素を見ながら手動で選択します。ちなみに、筆者は簡単な Webアプリを用意してブラウザでこの作業を行いましたが、この作業が最も時間がかかる作業でした。
この作業の成果物として以下のような CSVファイルが出来上がりました。簡単に言えば、ページ内の何番目のフォームの何番目のフォーム要素はどのカテゴリであるかを表すファイルです。
https://github.com/AsaiKen/form_inputter_for_blog/blob/master/static/category.csv
3.訓練と評価
さて、サンプルデータができたので、実際に機械学習モデルを訓練します。今回は線形回帰、線形SVM、非線形SVM、ExtraTrees、多層パーセプトロンをモデルに選びました。サンプルデータを訓練データとテストデータに分割した後、訓練データで訓練し、テストデータで性能を計測します。
ソースコード
https://github.com/AsaiKen/form_inputter_for_blog/blob/master/train.py
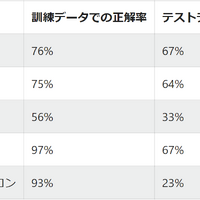
結果は以下となりました。なお、訓練データは 520 行、テストデータは 260 行です。
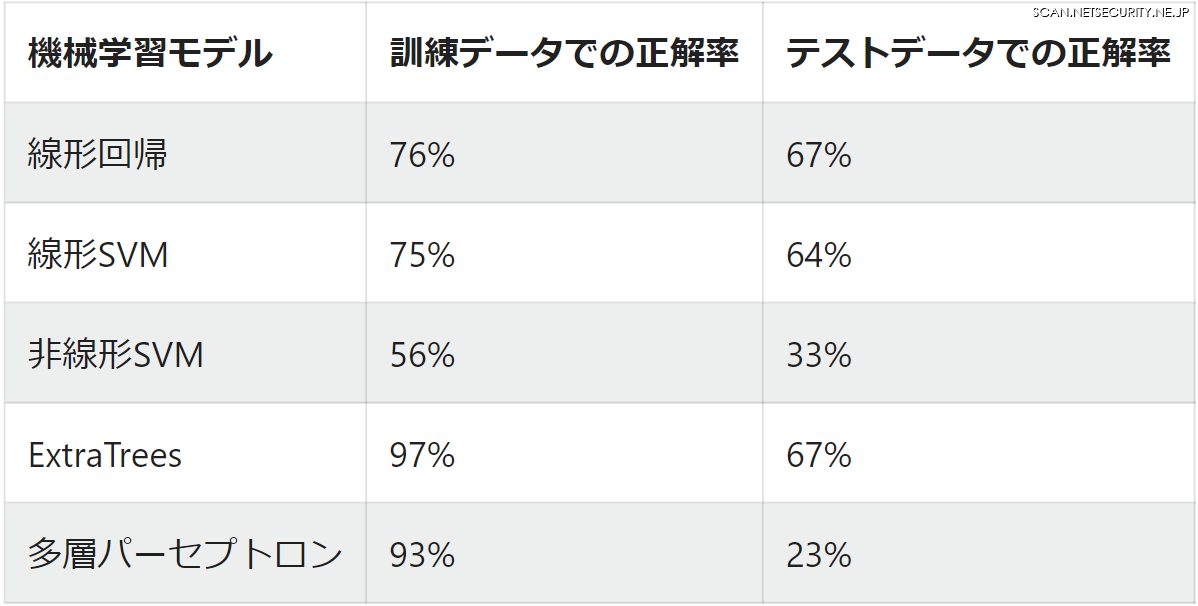
全体で見てみると、ランダムに回答する場合は正解率は 4 % 程度になるので、どのモデルもランダムよりは良い結果です。
個別で見てみると、どうやら線形モデルや、ExtraTrees のモデルが強いようです。ただ、正解率が 70 % 弱では実用には程遠いかと思います。これくらいの正解率であれば、経験則に基づいて手でプログラムを書いた方が性能が良さそうです。また、多層パーセプトロンは過学習を起こしているように見えます。モデルの複雑さに対してサンプルデータが少なすぎるのが原因でしょうか。
4.おわりに
いかがでしたでしょうか。今回は機械学習でフォーム要素の入力値を予測してみました。結果はイマイチでしたが、OCR の方法、フォーム要素の近くにあるテキストの選択方法、テキストを定量化するアルゴリズム、機械学習モデルのハイパーパラメータなど改良する余地はまだまだあります。また、誤判定しやすいカテゴリが無いかなどの結果の深掘りも必要です。そもそもで言えば、サンプルデータの少なさも問題です。やりたいことは尽きません。
ソースコード一式は以下のURLに置いておきます。
https://github.com/AsaiKen/form_inputter_for_blog